demo_cat_preds <- augment(tree_fit, demo_cats, eval_time = ((1:10) * 30))
demo_cat_preds |> select(1:3)
#> # A tibble: 50 × 3
#> .pred .pred_time event_time
#> <list> <dbl> <Surv>
#> 1 <tibble [10 × 5]> 1.08 36
#> 2 <tibble [10 × 5]> 0.594 16+
#> 3 <tibble [10 × 5]> 0.594 12+
#> 4 <tibble [10 × 5]> 1.08 16
#> 5 <tibble [10 × 5]> 2.39 22
#> 6 <tibble [10 × 5]> 0.594 16
#> 7 <tibble [10 × 5]> 1.08 294
#> 8 <tibble [10 × 5]> 0.594 68+
#> 9 <tibble [10 × 5]> 1.08 31
#> 10 <tibble [10 × 5]> 0.594 24+
#> # ℹ 40 more rows4 - Evaluating models
Survival analysis with tidymodels
Time-dependent metrics

Converting to events

Brier scores over evaluation time

ROC AUC over evaluation time

Your turn

Why haven’t we done this?
05:00
Cross-validation ![]()

set.seed(123)
cat_folds <- vfold_cv(cat_train, v = 10) # v = 10 is default
cat_folds
#> # 10-fold cross-validation
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [1588/177]> Fold01
#> 2 <split [1588/177]> Fold02
#> 3 <split [1588/177]> Fold03
#> 4 <split [1588/177]> Fold04
#> 5 <split [1588/177]> Fold05
#> 6 <split [1589/176]> Fold06
#> 7 <split [1589/176]> Fold07
#> 8 <split [1589/176]> Fold08
#> 9 <split [1589/176]> Fold09
#> 10 <split [1589/176]> Fold10Cross-validation ![]()
What is in this?
Set the seed when creating resamples
Bootstrapping ![]()
set.seed(3214)
bootstraps(cat_train)
#> # Bootstrap sampling
#> # A tibble: 25 × 2
#> splits id
#> <list> <chr>
#> 1 <split [1765/657]> Bootstrap01
#> 2 <split [1765/644]> Bootstrap02
#> 3 <split [1765/625]> Bootstrap03
#> 4 <split [1765/638]> Bootstrap04
#> 5 <split [1765/647]> Bootstrap05
#> 6 <split [1765/655]> Bootstrap06
#> 7 <split [1765/655]> Bootstrap07
#> 8 <split [1765/637]> Bootstrap08
#> 9 <split [1765/669]> Bootstrap09
#> 10 <split [1765/638]> Bootstrap10
#> # ℹ 15 more rowsThe whole game - status update
Evaluating model performance ![]()

tree_res |>
collect_metrics()
#> # A tibble: 4 × 7
#> .metric .estimator .eval_time mean n std_err .config
#> <chr> <chr> <dbl> <dbl> <int> <dbl> <chr>
#> 1 brier_survival standard 30 0.266 10 0.00498 Preprocessor1_Model1
#> 2 brier_survival standard 60 0.264 10 0.00952 Preprocessor1_Model1
#> 3 brier_survival standard 90 0.330 10 0.00599 Preprocessor1_Model1
#> 4 brier_survival standard 120 0.155 10 0.00978 Preprocessor1_Model1We can reliably measure performance using only the training data 🎉
Where are the fitted models? ![]()
tree_res
#> # Resampling results
#> # 10-fold cross-validation
#> # A tibble: 10 × 4
#> splits id .metrics .notes
#> <list> <chr> <list> <list>
#> 1 <split [1588/177]> Fold01 <tibble [4 × 5]> <tibble [0 × 3]>
#> 2 <split [1588/177]> Fold02 <tibble [4 × 5]> <tibble [0 × 3]>
#> 3 <split [1588/177]> Fold03 <tibble [4 × 5]> <tibble [0 × 3]>
#> 4 <split [1588/177]> Fold04 <tibble [4 × 5]> <tibble [0 × 3]>
#> 5 <split [1588/177]> Fold05 <tibble [4 × 5]> <tibble [0 × 3]>
#> 6 <split [1589/176]> Fold06 <tibble [4 × 5]> <tibble [0 × 3]>
#> 7 <split [1589/176]> Fold07 <tibble [4 × 5]> <tibble [0 × 3]>
#> 8 <split [1589/176]> Fold08 <tibble [4 × 5]> <tibble [0 × 3]>
#> 9 <split [1589/176]> Fold09 <tibble [4 × 5]> <tibble [0 × 3]>
#> 10 <split [1589/176]> Fold10 <tibble [4 × 5]> <tibble [0 × 3]>🗑️
But it’s easy to save the predictions ![]()
# Save the assessment set results
ctrl_cat <- control_resamples(save_pred = TRUE)
tree_res <- fit_resamples(tree_wflow, cat_folds, eval_time = c(90, 30, 60, 120),
control = ctrl_cat)
tree_res
#> # Resampling results
#> # 10-fold cross-validation
#> # A tibble: 10 × 5
#> splits id .metrics .notes .predictions
#> <list> <chr> <list> <list> <list>
#> 1 <split [1588/177]> Fold01 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 2 <split [1588/177]> Fold02 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 3 <split [1588/177]> Fold03 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 4 <split [1588/177]> Fold04 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 5 <split [1588/177]> Fold05 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 6 <split [1589/176]> Fold06 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 7 <split [1589/176]> Fold07 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 8 <split [1589/176]> Fold08 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 9 <split [1589/176]> Fold09 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>
#> 10 <split [1589/176]> Fold10 <tibble [4 × 5]> <tibble [0 × 3]> <tibble>But it’s easy to collect the predictions ![]()
tree_preds <- collect_predictions(tree_res)
tree_preds
#> # A tibble: 1,765 × 5
#> .pred id .row event_time .config
#> <list> <chr> <int> <Surv> <chr>
#> 1 <tibble [4 × 3]> Fold01 17 35 Preprocessor1_Model1
#> 2 <tibble [4 × 3]> Fold01 29 60 Preprocessor1_Model1
#> 3 <tibble [4 × 3]> Fold01 51 8 Preprocessor1_Model1
#> 4 <tibble [4 × 3]> Fold01 55 39+ Preprocessor1_Model1
#> 5 <tibble [4 × 3]> Fold01 62 36+ Preprocessor1_Model1
#> 6 <tibble [4 × 3]> Fold01 63 14 Preprocessor1_Model1
#> 7 <tibble [4 × 3]> Fold01 92 14+ Preprocessor1_Model1
#> 8 <tibble [4 × 3]> Fold01 95 37 Preprocessor1_Model1
#> 9 <tibble [4 × 3]> Fold01 96 19+ Preprocessor1_Model1
#> 10 <tibble [4 × 3]> Fold01 101 83 Preprocessor1_Model1
#> # ℹ 1,755 more rowsCreate a random forest model ![]()

Create a random forest model ![]()

rf_wflow <- workflow(event_time ~ ., rf_spec)
rf_wflow
#> ══ Workflow ══════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: rand_forest()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> event_time ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> Random Forest Model Specification (censored regression)
#>
#> Main Arguments:
#> trees = 1000
#>
#> Computational engine: aorsfYour turn
Use fit_resamples() and rf_wflow to:
- keep predictions
- compute metrics
08:00
Evaluating model performance ![]()
ctrl_cat <- control_resamples(save_pred = TRUE)
# Random forest uses random numbers so set the seed first
set.seed(2)
rf_res <- fit_resamples(rf_wflow, cat_folds, eval_time = c(90, 30, 60, 120),
control = ctrl_cat)
collect_metrics(rf_res)
#> # A tibble: 4 × 7
#> .metric .estimator .eval_time mean n std_err .config
#> <chr> <chr> <dbl> <dbl> <int> <dbl> <chr>
#> 1 brier_survival standard 30 0.210 10 0.00455 Preprocessor1_Model1
#> 2 brier_survival standard 60 0.241 10 0.00796 Preprocessor1_Model1
#> 3 brier_survival standard 90 0.199 10 0.00960 Preprocessor1_Model1
#> 4 brier_survival standard 120 0.151 10 0.00840 Preprocessor1_Model1The whole game - status update
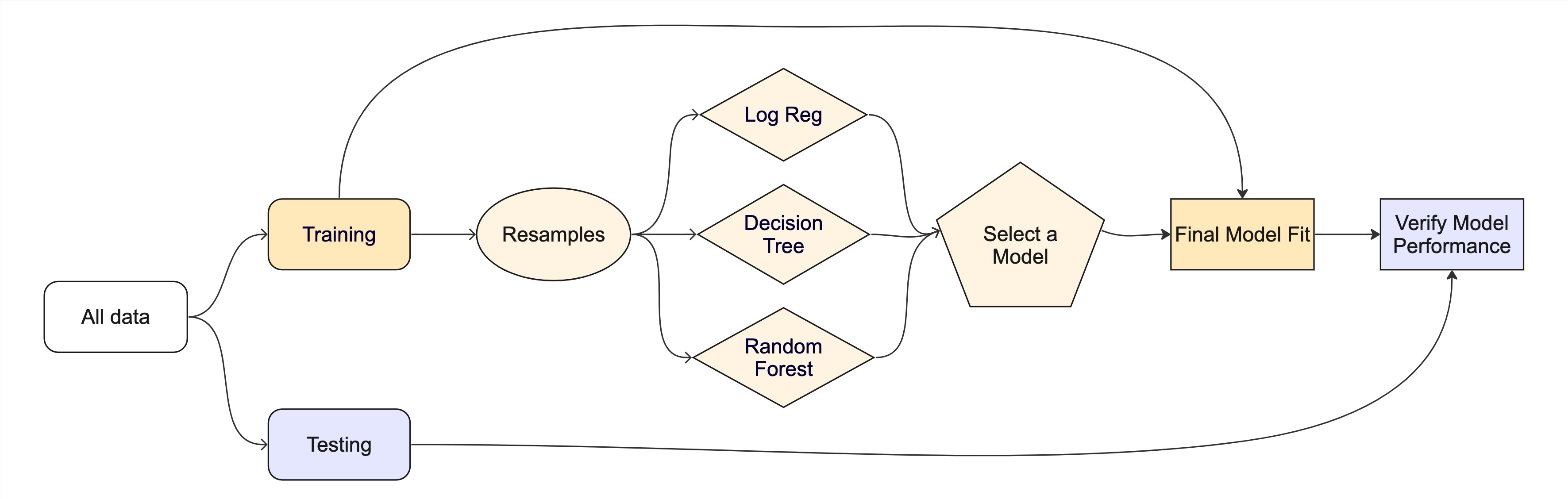
The final fit ![]()
Suppose that we are happy with our random forest model.
Let’s fit the model on the training set and verify our performance using the test set.
We’ve shown you fit() and predict() (+ augment()) but there is a shortcut:
# cat_split has train + test info
final_fit <- last_fit(rf_wflow, cat_split, eval_time = c(90, 30, 60, 120))
final_fit
#> # Resampling results
#> # Manual resampling
#> # A tibble: 1 × 6
#> splits id .metrics .notes .predictions .workflow
#> <list> <chr> <list> <list> <list> <list>
#> 1 <split [1765/442]> train/test split <tibble> <tibble> <tibble> <workflow>What is in final_fit? ![]()
collect_metrics(final_fit)
#> # A tibble: 4 × 5
#> .metric .estimator .eval_time .estimate .config
#> <chr> <chr> <dbl> <dbl> <chr>
#> 1 brier_survival standard 30 0.217 Preprocessor1_Model1
#> 2 brier_survival standard 60 0.225 Preprocessor1_Model1
#> 3 brier_survival standard 90 0.160 Preprocessor1_Model1
#> 4 brier_survival standard 120 0.108 Preprocessor1_Model1These are metrics computed with the test set
What is in final_fit? ![]()
extract_workflow(final_fit)
#> ══ Workflow [trained] ════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: rand_forest()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> event_time ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> ---------- Oblique random survival forest
#>
#> Linear combinations: Accelerated Cox regression
#> N observations: 1765
#> N events: 1116
#> N trees: 1000
#> N predictors total: 18
#> N predictors per node: 6
#> Average leaves per tree: 142.739
#> Min observations in leaf: 5
#> Min events in leaf: 1
#> OOB stat value: 0.63
#> OOB stat type: Harrell's C-index
#> Variable importance: anova
#>
#> -----------------------------------------Use this for prediction on new data, like for deploying
The whole game